How to solve the problem that the scraping is stopped without all the data being scraped? | Web Scraping Tool | ScrapeStorm
Abstract:Answer to "How to solve the problem that the scraping is stopped without all the data being scraped?" ScrapeStormFree Download
Question:
How to solve the problem that the scraping is stopped without all the data being scraped?
Answer:
1. Confirm whether the website requires login. The link copied from the browser will not save the login status, so you need to log in again in the software. Login is performed in the pre-login in the upper right corner of the software.
For more details, please refer to the tutorial:
How to scrape web pages that need to be logged in to view
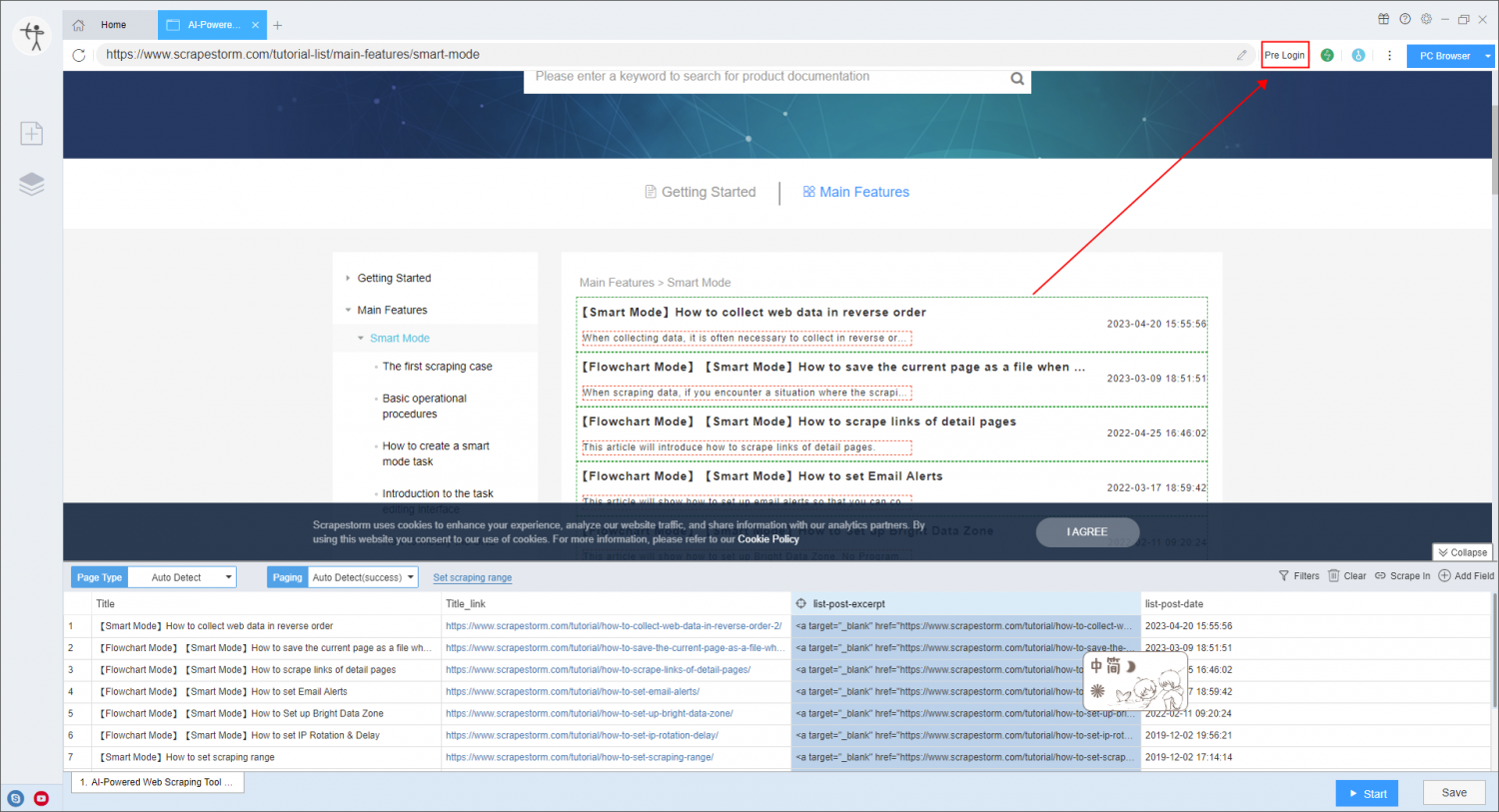
2. Confirm the data that can actually be viewed on the webpage, not the data that is searched, but the amount of data that can actually be viewed on the webpage. Some websites display tens of thousands of data, but only a few thousand can be viewed in reality. It is recommended to manually jump to the last page to see the actual data volume.
3. Click “Show Page” to confirm the opening status of the webpage when the task is actually running, whether it is restricted, and whether there is a pop-up window.
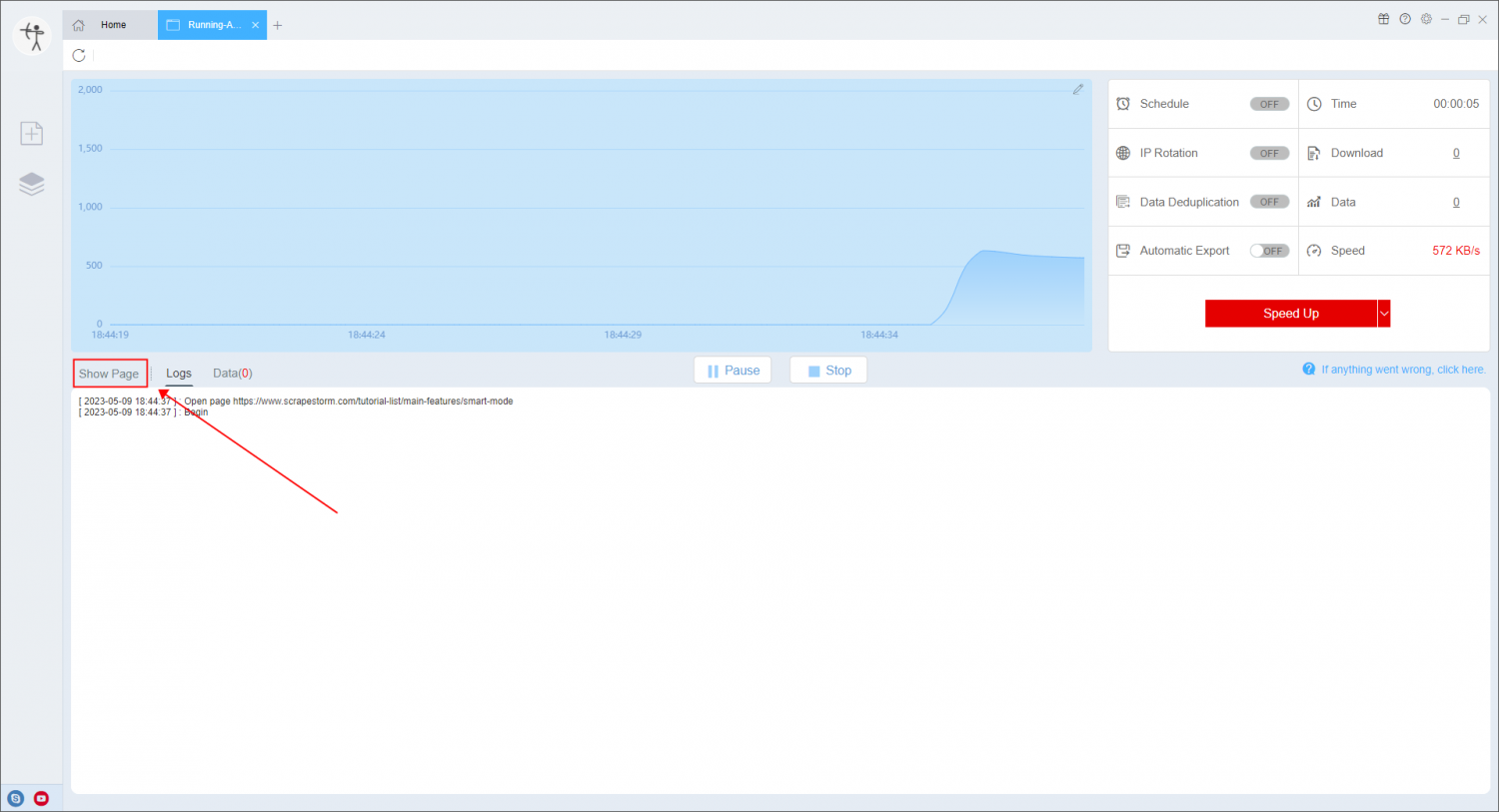
For more details, please refer to the tutorial:
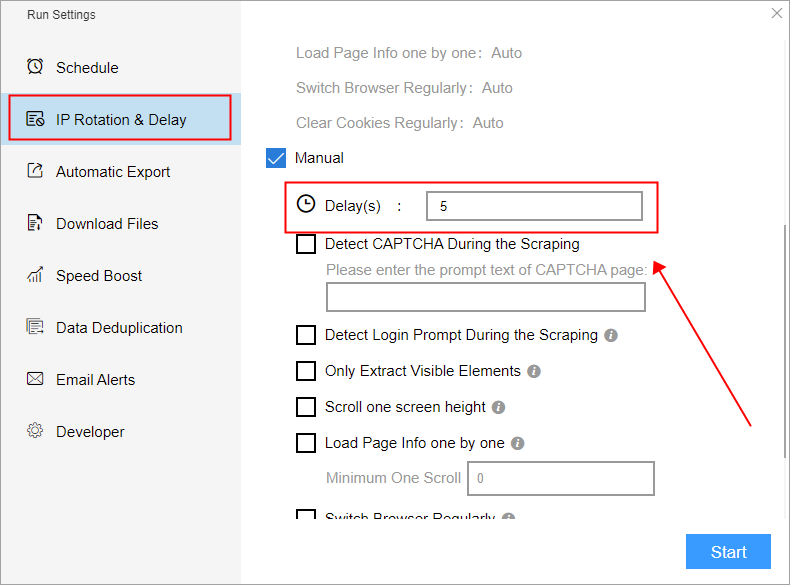
5. If all the data can be viewed on the webpage without being restricted, then it may be a problem with the network speed. The software repeatedly scraped the webpage several times but did not load the webpage. At this time, you can try to set the delay in IP Rotation & Dealy.
6. After all the steps of the appeal have been performed, or not all the data has been scraped, check whether the URL will change as the page number changes. If it will change, directly copy the URL at the end position of the scraping, paste it into the software, and stop The part starts scraping.
For more details, please refer to the tutorial: